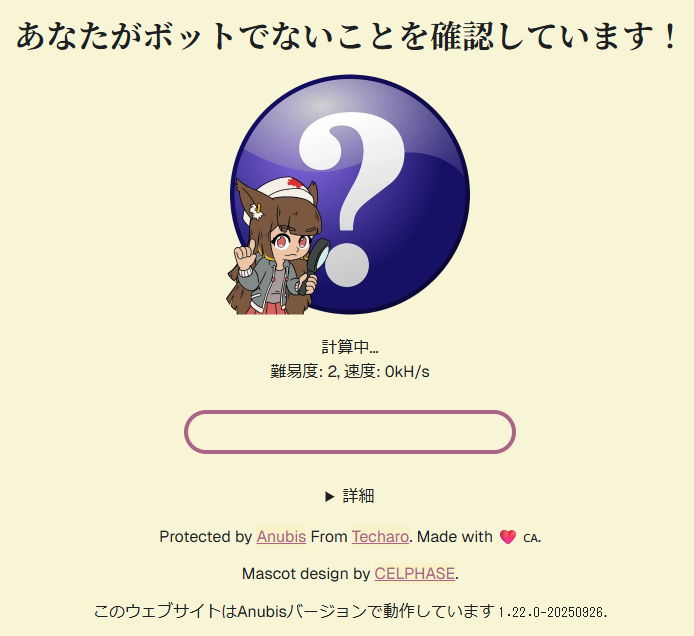
悪名高いAnubisだが、さすがにサーバー負荷高すぎて操作不能なのでやむなし……。
相変わらずPleromaサーバーの運営を続けているわけですが、そのソースコードを管理するためにForgejoサーバーを立てています。一時期はAWS上で動いていましたが、絶えず続くスクレイパーからのリクエストで結構な金額がかかっていました。そこで自宅のノートPCに移行してみたのですが、自分の作業のために使うにも重すぎて、使い物になりませんでした。
ここで、スクレイパーに対する僕の立場を表明しておきます。
- robots.txtは設定済み。特にインデックスしても面白いものはないので、全部Disallowしてあります。
- AIに学習されることは何ら構いません。
- でも、重いリクエストを無駄に投げられることは勘弁。
まずはリバースプロキシとして使っているnginxだけで何とかできないか考えましたが、limit_reqやlimit_connだけでは、通常の人間の操作まで邪魔してしまう設定しかできずに断念しました。というのも、スクレイパーによる被害は、リクエスト数が多いことではなく、重いエンドポイント(昔のコミットを見たり、blameしたり、リポジトリ全体アーカイブzipをダウンロードしたり)へのアクセスでした。例えば1分間に2リクエストまで許可する、みたいな制限をかけたとしても、2回リポジトリ全体ダウンロードをやられたらたまったもんじゃないです。さらに、同時にやってくるスクレイパーは数種類いるっぽく、IPアドレス単位で制限してもすり抜けられます。
というわけで、嫌いで仕方なかったAnubisに手を出すことにしました。